

Imagine a librarian who fetches and summarizes the perfect book for your query—instantly. That’s Retrieval Augmented Generation (RAG), an AI innovation that pairs real-time information retrieval with natural language generation. Unlike traditional models prone to outdated or invented answers, RAG first scours databases or documents for precise information, then crafts responses grounded in those facts.
Pioneered by Meta AI researchers in 2020, RAG now underpins enterprise chatbots, data analysts, and virtual assistants, enabling insights with verifiable accuracy. For businesses drowning in data but starving for actionable answers, RAG is the bridge.
In this guide, we’ll explore how RAG bridges the gap between data overload and precise decision-making—and how you can harness it to turn information into innovation.
What is RAG in AI?
Retrieval-Augmented Generation (RAG) is an AI framework that combines two critical steps to deliver accurate, context-aware answers: it first retrieves relevant information from external sources (like databases, documents, or real-time data) and then generates natural-language responses using a language model.
Unlike standard AI systems that rely solely on pre-trained knowledge—which can become outdated or invent plausible-sounding errors—RAG grounds answers in verified, up-to-date information. This makes it ideal for applications like customer service bots, medical advice tools, or enterprise search engines, where precision, traceability, and trustworthiness are essential. By bridging dynamic data retrieval with fluent text generation, RAG transforms raw information into actionable insights.
How do RAG systems work with LLMs?
Retrieval-Augmented Generation (RAG) systems enhance language models by integrating real-time data retrieval with text generation. Here’s a step-by-step breakdown of their operation:
Input Query Processing
The system receives a user question (e.g., ‘What are the latest breakthroughs in solar power?’), RAG converts your words into a format machines understand, like translating human language into a ‘searchable’ code. This helps the system grasp the intent and meaning behind your query.
Retrieval Phase:
The system checks your question against a massive digital library (like research papers, articles, or company files) that’s been pre-organized for quick access. Think of it like a librarian scanning shelves of books tagged by topic. The retrieved documents are concatenated with the original query to form an augmented input. This provides context for the generator, grounding it in factual, up-to-date information.
Using smart algorithms, it identifies the documents most closely related to your question—similar to how Google prioritizes top search results, but focused on meaning, not just keywords. This happens in milliseconds, even with billions of data points.
Generation Phase:
The AI then blends your question with the retrieved information to craft a clear, natural answer. By combining both elements, it ensures responses are not just fluent but also factually aligned with the sources.
Output Delivery:
The final response is returned to the user, combining fluency (from the generator) with factual grounding (from retrieval).
How RAG works in a diagram
Retrieval-Augmented Generation (RAG) merges real-time research with AI writing: first it fetches the best data, then crafts human-like answers. The diagram below shows how this two-step process turns questions into precise, sourced responses—like a digital expert thinking aloud.
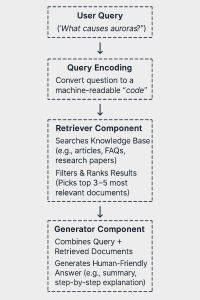
How is RAG implemented?
RAG integrates two core components—retrieval (searching for relevant data) and generation (writing answers)—to create AI systems that combine factual accuracy with natural language fluency. Here’s how it works in practice:
1. Build a “Knowledge Bank”
- Step 1: Collect all the information the AI needs to reference—manuals, FAQs, articles, or databases.
Example: A bank might load its loan policies, fee schedules, and customer service scripts. - Step 2: Clean and organize the data.
- Remove duplicates or outdated entries (e.g., old refund policies).
- Tag documents by topic (e.g., “billing,” “technical support”) for faster searching
2. Train the AI to “Find Answers” (Retriever Setup)
Goal: Convert questions into searchable formats and match them to your documents.
- Step 1: Turn questions into “meaning codes”
Use semantic encoding tools (like BERT-based models) to convert questions (e.g., “What’s the wire transfer fee?”) into unique numeric representations that capture their meaning.
- Step 2: Compare codes to your knowledge bank
Use a vector database (e.g., FAISS, Pinecone) to pre-index documents into similar numeric codes.
For each question, search the database for the top 3-5 closest matches (e.g., fee schedules tagged “wire transfers”).
- Step 3: Extract relevant text snippets
Pull key sections from the matched documents (e.g., “Domestic wire fee: $25” from a policy PDF).
3. Train the AI to “Write Answers” (Generator Setup)
Goal: Force the AI to use retrieved snippets when generating responses.
- Step 1: Combine question + snippets into a prompt
Feed the AI the user’s question alongside the retrieved text.
- Step 2: Train the AI to follow the context
Use pre-trained language models (like GPT-3.5 or Llama 2) and fine-tune them with examples where answers strictly align with the provided snippets.
Provide feedback if the AI invents details (e.g., rejecting answers that add unsupported fees like “$30”).
- Step 3: Add validation rules
Ensure answers cite sources (e.g., “per Section 2.1 of the 2024 fee guide”).
Flag answers that include numbers, terms, or claims not found in the retrieved documents.
What are some common applications of RAG?
Customer Support & Chatbots
- Use Case: Answering FAQs, troubleshooting, or resolving policy-based queries.
- Why RAG?
- Pulls answers directly from company documents (e.g., refund policies, product manuals).
- Avoids generic or incorrect replies.
- Example: A telecom chatbot resolves billing questions by citing the latest pricing sheets.
Enterprise Knowledge Management
- Use Case: Helping employees find internal information (e.g., HR policies, technical guidelines).
- Why RAG?
- Searches across siloed databases, Slack threads, or SharePoint files.
- Example: “How do I submit an expense report?” and it retrieves the 2024 finance policy.
Healthcare & Medical Advice
- Use Case: Providing symptom checks, drug interactions, or treatment guidelines.
- Why RAG?
- Grounds answers in peer-reviewed studies or hospital protocols.
- Example: A patient asks, “Can I take ibuprofen with blood thinners?” and it cites the latest NIH guidelines.
Education & Tutoring
- Use Case: Explaining complex topics (e.g., math problems, historical events).
- Why RAG?
- Combines textbook content with tailored explanations.
- Example: A student asks, “What caused the French Revolution?” → Summarizes key causes from verified sources.
Legal & Compliance
- Use Case: Analyzing contracts, summarizing regulations, or answering compliance questions.
- Why RAG?
- Pulls from legal databases (e.g., GDPR rules, case law).
- Example: “What’s the penalty for a data breach in the EU?” → Quotes Article 83 of GDPR.
Market Research & Data Analysis
- Use Case: Extracting insights from reports, earnings calls, or competitor data.
- Why RAG?
- Generates summaries from terabytes of unstructured data.
- Example: “What are Tesla’s Q2 2024 sales trends?” → Analyzes SEC filings and press releases.
Content Moderation
- Use Case: Flagging harmful content or verifying claims in user posts.
- Why RAG?
- Cross-references posts against fact-checked databases.
- Example: Detects a viral health myth by comparing it to WHO guidelines.
Personalized Recommendations
- Use Case: Suggesting products, articles, or services based on user history.
- Why RAG?
- Combines user preferences with real-time inventory or content libraries.
- Example: “Recommend hiking gear under $100” → Pulls from a retailer’s catalog.
Which LLM uses RAG?
RAG (Retrieval-Augmented Generation) is not a standalone LLM but a framework that enhances existing language models by combining them with a retrieval system. Many popular LLMs can be integrated with RAG to improve accuracy and reduce hallucinations. Here’s a breakdown:
LLMs Commonly Paired with RAG
| LLM | Use Case with RAG | Example Tools/Frameworks |
| GPT-4 | Customer support, research assistants, enterprise knowledge bases. | OpenAI API + Pinecone/FAISS |
| Llama 2 | Open-source projects, internal document Q&A, compliance checks. | Hugging Face Transformers + LangChain |
| Claude | Legal analysis, medical advice, fact-checking. | Anthropic API + Elasticsearch |
| BERT | Semantic search, document retrieval (often as the retriever component). | Sentence-BERT + Haystack |
| T5 | Summarization, translation with source grounding. | Hugging Face + Vector databases |
| PaLM | Enterprise automation, data analysis with real-time data. | Google Cloud AI + Vertex AI |
RAG Vs. LLMs
While both Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs) are pillars of modern AI, they solve problems in fundamentally different ways. Here’s a breakdown of their roles, strengths, and limitations:
Core Definitions
| Aspect | LLM | RAG |
| What It Is | A standalone generative model trained on vast text data. | A framework that combines an LLM with a retrieval system to access external data. |
| Primary Goal | Generate human-like text based on learned patterns. | Generate answers grounded in external, real-time data. |
How They Work
| LLM | RAG |
| – Relies solely on pre-trained knowledge (up to its training cutoff date). – Answers are generated from memorized patterns in its training data. |
– Retrieves relevant documents from a database/API before generating a response. – Combines the LLM’s generative power with external, up-to-date data. |
Strengths
| LLM | RAG |
| ✅ Creative writing (stories, poems, code). ✅ General-purpose tasks (summarization, translation). ✅ Low latency (no external lookups). |
✅ Factual accuracy (answers tied to sources). ✅ Dynamic knowledge (uses real-time or domain-specific data). ✅ Reduces “hallucinations” (made-up facts). |
Weaknesses
| LLM | RAG |
| ❌ Outdated knowledge (e.g., post-2021 events for GPT-3.5). ❌ Prone to hallucinations (plausible but incorrect answers). ❌ No traceability (can’t cite sources). |
❌ Higher complexity (requires retrieval setup). ❌ Slower responses due to retrieval steps. ❌ Dependent on data quality (garbage in → garbage out). |
When to Use Which
| Use LLM If… | Use RAG If… |
| – You need creative or general-purpose text generation. – Tasks don’t require real-time or domain-specific data. – Speed is critical. |
– Answers must be factually accurate and sourced. – You need access to up-to-date or proprietary data. – Auditability matters (e.g., legal, medical use cases). |
Conclusion
RAG merges the best of search and generative AI, delivering accurate, sourced answers by grounding responses in real-time data. Unlike traditional LLMs, it reduces hallucinations and stays updated without retraining. A game-changer for industries where precision and trust matter—turning data into reliable insights, one query at a time.



